Détection des Anomalies Avec Machine learing en Java

Rapport de Projet : Détection des Anomalies dans les Connexions Utilisateurs
1. Introduction
Contexte du projet
Ce projet a pour objectif d’analyser des logs de connexions utilisateurs afin de détecter des anomalies dans le comportement des utilisateurs. Plus précisément, nous nous concentrons sur l’identification des connexions suspectes qui se produisent après 16h00, ce qui pourrait indiquer des tentatives d’accès non autorisées ou des comportements atypiques.
Les logs contiennent des informations sur l’heure des connexions ainsi que sur l’identifiant des utilisateurs, et il est important de comprendre si certains utilisateurs se connectent à des moments anormaux, ce qui pourrait être interprété comme une anomalie.
Objectifs
Les objectifs principaux de ce projet sont :
- Analyser les logs des utilisateurs pour repérer les comportements anormaux dans leurs connexions.
- Identifier les connexions ayant lieu après 16h00, qui sont considérées comme suspectes en raison de leur caractère atypique.
- Utiliser des algorithmes d’apprentissage automatique pour détecter ces anomalies de manière automatique.
- Visualiser les résultats d’une manière claire pour faciliter l’interprétation des anomalies détectées.
2. Méthodologie
A. Collecte des logs
Intégration des logs avec Log4j2
Dans notre projet, l’enregistrement et la gestion des logs jouent un rôle crucial pour suivre l’évolution des connexions et détecter les anomalies. Nous avons utilisé Log4j2, un framework de logging puissant et flexible, pour gérer et formater les logs générés dans notre application Java.
Dans le code Java, chaque événement de connexion est enregistré avec des informations telles que l’ID utilisateur, le timestamp de la connexion, et le message décrivant l’événement (par exemple, “Connexion_réussie”). Ce processus de logging est orchestré par la bibliothèque Log4j2, configurée via un fichier XML.
Ci-dessous, le code Java permettant de générer les logs :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
package com.exemple;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.ThreadContext;
public class LogGenerator {
private static final Logger logger = LogManager.getLogger(LogGenerator.class);
private static final Random random = new Random();
// Liste des ID récurrents
private static final List<String> recurringUserIDs = Arrays.asList("75689", "18410", "46202", "4985", "3643");
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS");
private static String generateUserID() {
// 60% chance d'utiliser un ID récurrent
if (random.nextInt(10) < 6) {
return recurringUserIDs.get(random.nextInt(recurringUserIDs.size()));
} else {
int id = random.nextInt(100000) + 1;
return String.valueOf(id);
}
}
int minute = random.nextInt(60);
int second = random.nextInt(60);
int millisecond = random.nextInt(1000);
// Générer un timestamp entre 9h et 16h
private static String generateTimestampBetween9and16() {
int hour = random.nextInt(8) + 9; // Heure entre 9 et 16
LocalDateTime now = LocalDateTime.now().withHour(hour).withMinute(minute).withSecond(second).withNano(millisecond * 1_000_000);
return now.format(formatter);
}
// Générer un timestamp après 16h
private static String generateTimestampAfter16h() {
int hour = random.nextInt(8) + 16; // Heure entre 16 et 23
int millisecond = random.nextInt(1000);
LocalDateTime now = LocalDateTime.now().withHour(hour).withMinute(minute).withSecond(second).withNano(millisecond * 1_000_000);
return now.format(formatter);
}
public static void main(String[] args) throws InterruptedException {
// Générer 500 logs entre 9h et 16h
for (int i = 0; i < 500; i++) {
String userID = generateUserID();
String timestamp = generateTimestampBetween9and16();
ThreadContext.put("userID", userID);
ThreadContext.put("timestamp", timestamp);
logger.info("Connexion_réussie");
ThreadContext.clearAll();
}
// Générer 15 logs après 16h
for (int i = 0; i < 15; i++) {
String userID = generateUserID();
String timestamp = generateTimestampAfter16h();
ThreadContext.put("userID", userID);
ThreadContext.put("timestamp", timestamp);
logger.info("Connexion_réussie");
ThreadContext.clearAll();
}
}
}
Le programme génère 515 logs au total, avec des informations dynamiques sur les utilisateurs et les timestamps. Ces logs simulent des connexions réussies d’utilisateurs, réparties entre les périodes avant et après 16h, et sont enregistrées avec Log4j. Les timestamps et les IDs des utilisateurs sont générés de manière aléatoire.
Chaque log généré est ensuite traité par une configuration Log4j2 définie dans le fichier XML suivant, qui précise comment et où les logs doivent être enregistrés.
Configuration Log4j2
Le fichier XML de configuration Log4j2 permet de spécifier les paramètres suivants :
- Le format des logs.
- La gestion des fichiers logs, incluant la rotation et la suppression automatique des anciens fichiers.
- L’enregistrement des logs à la fois dans un fichier et sur la console pour une surveillance en temps réel.
Voici la configuration détaillée de Log4j2 utilisée pour ce projet :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="INFO">
<Properties>
<Property name="basePath">C:/Users/pc/personnel/etude_GTR2/java/project/Detection_anomalie_java/docker</Property>
</Properties>
<Appenders>
<RollingFile name="LogFile"
fileName="${basePath}/java_logs.log"
filePattern="${basePath}/java_logs-%d{yyyy-MM-dd}.log">
<PatternLayout pattern="%X{timestamp} [%t] %level %X{userID} %msg%n" />
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
<SizeBasedTriggeringPolicy size="10MB"/>
</Policies>
<DefaultRolloverStrategy max="10">
<Delete basePath="${basePath}" maxDepth="2">
<IfLastModified age="30d"/>
</Delete>
</DefaultRolloverStrategy>
</RollingFile>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout>
<Pattern>%X{timestamp} [%t] %level %msg%n</Pattern>
</PatternLayout>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="LogFile"/>
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
Explication de la configuration
1. Propriétés :
1
2
3
<Properties>
<Property name="basePath">C:/Users/pc/personnel/etude_GTR2/java/project/Detection_anomalie_java/docker</Property>
</Properties>
- Propriétés : La section
<Properties>définit les variables globales pour la configuration. Dans ce cas, une propriété nomméebasePathest définie, ce qui permet de centraliser le chemin du répertoire où les fichiers de logs seront enregistrés. Cela permet de facilement modifier le chemin des fichiers de logs sans avoir à modifier plusieurs endroits dans la configuration.
2. Appenders :
Les appenders sont des composants qui définissent comment les logs doivent être traités et où ils doivent être envoyés (fichier, console, etc.).
a. RollingFile Appender :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<RollingFile name="LogFile"
fileName="${basePath}/java_logs.log"
filePattern="${basePath}/java_logs-%d{yyyy-MM-dd}.log">
<PatternLayout pattern="%X{timestamp} [%t] %level %X{userID} %msg%n" />
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
<SizeBasedTriggeringPolicy size="10MB"/>
</Policies>
<DefaultRolloverStrategy max="10">
<Delete basePath="${basePath}" maxDepth="2">
<IfLastModified age="30d"/>
</Delete>
</DefaultRolloverStrategy>
</RollingFile>
RollingFile: Cet appender enregistre les logs dans un fichier et applique des politiques de rotation pour ne pas surcharger l’espace disque.fileNameetfilePattern:fileNamedéfinit le nom du fichier principal où les logs sont enregistrés (java_logs.log).filePatterndéfinit le modèle de nom pour les fichiers archivés (par exemple,java_logs-2024-12-09.log), en fonction de la date d’archivage.
PatternLayout: Définit le format des logs. Dans ce cas, chaque ligne de log aura le format suivant :%X{timestamp}: Ajoute le timestamp de l’événement logué.[%t]: Affiche le nom du thread.%level: Le niveau de log (INFO, ERROR, etc.).%X{userID}: Ajoute l’ID de l’utilisateur, stocké dans leThreadContext.%msg: Le message du log (ici, “Connexion_réussie”).%n: Saut de ligne à la fin du log.
Policies:TimeBasedTriggeringPolicy: Rotation basée sur le temps, ici tous les jours (interval="1").SizeBasedTriggeringPolicy: Rotation basée sur la taille du fichier, ici après 10MB.
DefaultRolloverStrategy: Définie la stratégie de conservation des logs :max="10": Garde un maximum de 10 fichiers de logs.Delete: Supprime les fichiers de logs plus anciens que 30 jours.
b. Console Appender :
1
2
3
4
5
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout>
<Pattern>%X{timestamp} [%t] %level %msg%n</Pattern>
</PatternLayout>
</Console>
- Console Appender : Envoie les logs à la sortie standard (console).
- Le format des logs dans la console est similaire à celui du fichier, sauf qu’il n’inclut pas l’ID utilisateur. Cela pourrait être utile pour les logs qui ne nécessitent pas de traçabilité par utilisateur.
3. Loggers :
1
2
3
4
5
6
<Loggers>
<Root level="info">
<AppenderRef ref="LogFile"/>
<AppenderRef ref="Console"/>
</Root>
</Loggers>
RootLogger :- Le logger racine (
Root) est le point d’entrée pour tous les logs dans l’application. - Le niveau de log est défini à
info, ce qui signifie que seuls les logs de niveauINFOet plus graves (WARN, ERROR, etc.) seront enregistrés. AppenderRef: Fait référence aux appenders définis précédemment, donc les logs seront envoyés à la fois au fichier (LogFile) et à la console (Console).
- Le logger racine (
Résumé
- Gestion des logs dans un fichier : Les logs sont enregistrés dans un fichier, avec une rotation basée sur le temps et la taille du fichier. Les fichiers plus anciens sont automatiquement supprimés après 30 jours.
- Logs formatés : Chaque log inclut un timestamp, un ID utilisateur, et le message, ce qui permet une bonne traçabilité des événements.
- Sortie Console : Les logs sont également envoyés à la console, mais sans l’ID utilisateur.
- Politique de rotation : Les fichiers de log sont organisés et archivés en fonction de la taille et du temps, avec un maximum de 10 fichiers de logs conservés.
Ce fichier de configuration Log4j2 permet de configurer efficacement la gestion des logs dans une application Java, avec des options flexibles pour la rotation des fichiers et un affichage en temps réel dans la console.
1
2
3
4
5
6
7
8
9
10
11
2024-12-09 16:49:57.246 [main] INFO 89890 Connexion_réussie
2024-12-09 15:54:44.825 [main] INFO 23721 Connexion_réussie
2024-12-09 15:21:34.231 [main] INFO 70187 Connexion_réussie
2024-12-09 09:04:27.830 [main] INFO 73530 Connexion_réussie
2024-12-09 16:41:54.174 [main] INFO 99727 Connexion_réussie
2024-12-09 11:31:40.878 [main] INFO 1054 Connexion_réussie
2024-12-09 15:24:50.953 [main] INFO 75689 Connexion_réussie
2024-12-09 14:19:50.550 [main] INFO 18410 Connexion_réussie
2024-12-09 16:07:09.340 [main] INFO 46202 Connexion_réussie
2024-12-09 12:19:21.987 [main] INFO 4985 Connexion_réussie
2024-12-09 15:55:25.038 [main] INFO 3643 Connexion_réussie
Chaque ligne de log contient une date et une heure, un niveau de log (INFO), l’identifiant d’un utilisateur et un message décrivant l’événement. Le but est de détecter les utilisateurs qui se connectent après 16h00, ce qui constitue un comportement atypique.
B. Traitement des Logs avec Logstash et Envoi à Elasticsearch
Introduction
Une fois les logs générés et stockés dans des fichiers par l’application Java (comme détaillé précédemment), il est essentiel de traiter et d’analyser ces données pour détecter les anomalies. Pour cela, nous utilisons Logstash, un outil puissant pour l’ingestion, le traitement et le transfert de données vers Elasticsearch, une base de données orientée recherche, qui nous permet d’analyser ces logs de manière performante.
Dans cette section, nous expliquons comment Logstash récupère les logs, les traite, puis les envoie à Elasticsearch, tout en utilisant Docker pour simplifier le déploiement et la gestion des services.
Configuration de Logstash
Récupération des Logs avec Logstash
Logstash est configuré pour récupérer les logs générés par notre application Java. Pour cela, nous utilisons un fichier de configuration Logstash qui définit l’entrée, le filtre et la sortie des données.
Voici un exemple de fichier de configuration Logstash (logstash.conf), utilisé pour récupérer les logs à partir des fichiers stockés par Log4j2, les traiter, puis les envoyer à Elasticsearch :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
input {
file {
path => "/usr/share/logstash/logs/java_logs.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
mutate {
gsub => [
"message", "\r", "",
"message", "\n", ""
]
}
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{DATA:thread}\] %{LOGLEVEL:level} %{NUMBER:userID} %{DATA:message}"
}
tag_on_failure => ["_grokparsefailure_debug"]
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
# Débogage pour afficher le message grok échoué
if "_grokparsefailure_debug" in [tags] {
stdout { codec => rubydebug }
}
}
Dans ce fichier :
- input : Logstash est configuré pour lire les fichiers de log générés par l’application Java. Le chemin d’accès au fichier est spécifié dans
path. - filter : Un filtre est appliqué pour traiter les données, comme ajouter un champ personnalisé.
- output : Les logs sont envoyés vers Elasticsearch, qui est hébergé localement (http://localhost:9200), et stockés dans un index du type
logs-YYYY.MM.DD.
Déploiement de Logstash et Elasticsearch avec Docker
Pour simplifier le déploiement de ces services, nous utilisons Docker. Docker nous permet d’exécuter Logstash et Elasticsearch dans des conteneurs isolés, évitant ainsi toute configuration manuelle complexe et garantissant la portabilité du projet.
Voici les étapes pour déployer Logstash et Elasticsearch avec Docker.
a. Docker Compose pour Logstash et Elasticsearch
Docker Compose est utilisé pour définir et exécuter plusieurs conteneurs Docker en même temps. Voici un exemple de fichier docker-compose.yml pour démarrer Elasticsearch et Logstash.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.16.1
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false # Désactive la sécurité pour simplifier le projet initial
ports:
- "9200:9200"
- "9300:9300"
networks:
- elk
logstash:
image: docker.elastic.co/logstash/logstash:8.10.0
container_name: logstash
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf # Montage du fichier de configuration
- ./java_logs.log:/usr/share/logstash/logs/java_logs.log # Répertoire contenant vos logs
ports:
- "5044:5044" # Port pour l'envoi des logs
depends_on:
- elasticsearch
networks:
- elk
kibana:
image: docker.elastic.co/kibana/kibana:8.16.1
container_name: kibana
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
networks:
- elk
networks:
elk:
driver: bridge
Ce fichier compose contient :
- Elasticsearch : Déploie un conteneur Elasticsearch exposé sur le port 9200.
- Logstash : Déploie un conteneur Logstash et lui permet d’utiliser le fichier de configuration
logstash.confpour traiter les logs.
b. Lancer les Services
Pour lancer les services Elasticsearch et Logstash avec Docker Compose, exécutez les commandes suivantes dans le répertoire où se trouve le fichier docker-compose.yml :
1
docker-compose up
Cela démarrera Elasticsearch et Logstash, en les connectant au réseau elk. Logstash commencera à récupérer les logs générés par l’application Java, les traitera et les enverra à Elasticsearch pour une analyse approfondie.
Conclusion
En combinant Logstash, Elasticsearch et Docker, nous avons mis en place une solution robuste pour collecter, traiter et analyser les logs générés par l’application Java. Cela nous permet de détecter les anomalies dans les connexions utilisateur, et d’envoyer les données à Elasticsearch pour une analyse plus poussée. L’utilisation de Docker simplifie grandement le processus de déploiement et assure la portabilité de la solution.
D’accord, plongeons plus profondément dans le fonctionnement d’Isolation Forest pour la détection d’anomalies, avec des explications détaillées, des exemples pratiques et une exploration plus complète des concepts mathématiques sous-jacents. L’objectif est de donner une compréhension approfondie de la manière dont cet algorithme fonctionne, comment il est appliqué dans notre projet de détection d’anomalies dans les logs de connexion, et d’expliquer chaque étape de manière claire.
C. Principe de Base de l’Isolation Forest
Introduction
L’idée derrière Isolation Forest est que les anomalies dans un jeu de données sont souvent isolables plus rapidement que les points de données normaux. Cela est dû au fait que les anomalies sont loin de la masse des données “normales”, et par conséquent, nécessitent moins de divisions pour être isolées.
Imaginons un ensemble de données en 2D, où chaque point représente une observation dans notre jeu de données, par exemple des connexions utilisateurs avec des caractéristiques comme l’ID utilisateur et l’heure de connexion. Les points normaux seront généralement proches les uns des autres, tandis que les anomalies (par exemple, des connexions inhabituelles) seront éloignées du groupe principal.
L’algorithme Isolation Forest tire parti de cette caractéristique en construisant des arbres binaires d’isolement. L’algorithme divise de manière répétée l’espace des données jusqu’à ce qu’il isole chaque point. Les anomalies sont isolées en moins de coupures, tandis que les points normaux nécessitent plus de coupures pour être séparés.
1. Construction des Arbres d’Isolement
Isolation Forest construit un certain nombre d’arbres binaires appelés Isolation Trees. Voici les étapes détaillées de leur construction :
Sélection d’une caractéristique : À chaque niveau de l’arbre, une caractéristique parmi celles disponibles dans les données est choisie au hasard. Dans notre cas, cela pourrait être l’ID utilisateur, l’heure de connexion, ou tout autre attribut pertinent.
Sélection d’un seuil : Une valeur seuil est choisie pour diviser les données. Par exemple, si l’attribut est l’heure de connexion, la valeur seuil pourrait être 14h. Ce seuil divise l’ensemble des données en deux groupes : ceux dont l’heure est avant 14h et ceux après.
Répétition du processus : Le processus est répété de manière récursive sur les sous-ensembles de données jusqu’à ce que chaque point soit isolé. Cela continue jusqu’à ce qu’un critère d’arrêt soit atteint, tel qu’un nombre maximum de niveaux d’arbre ou un nombre minimum de points dans un sous-ensemble.
Un exemple illustratif pourrait être :
- Imaginez que vous ayez des données où la majorité des connexions se produisent entre 8h et 17h, mais certaines connexions suspectes ont lieu à 3h du matin. Lorsque l’algorithme construit des arbres binaires, il trouvera que ces connexions sont isolées plus rapidement que les autres, car elles sont en dehors de la plage horaire habituelle.
2. Calcul de la Profondeur d’Isolement (H(x))
La clé du fonctionnement de Isolation Forest réside dans la mesure de la profondeur d’isolement d’un point donné \(x_i\), qui est le nombre de divisions nécessaires pour isoler ce point des autres.
- Si un point est isolé rapidement, la profondeur d’isolement sera faible.
- Si un point nécessite plusieurs divisions, la profondeur d’isolement sera plus grande.
Soit \(H(x)\) la profondeur d’isolement d’un point \(x\). Plus \(H(x)\) est faible, plus le point est une anomalie.
Calcul de la Profondeur Moyenne de l’Arbre
L’algorithme construit plusieurs arbres. Pour un arbre donné, la profondeur d’isolement d’un point est calculée de manière récursive. La profondeur moyenne d’isolement, \(H(x)\), est ensuite calculée sur l’ensemble des arbres. Plus la profondeur est faible, plus le point est susceptible d’être une anomalie.
La profondeur d’isolement moyenne pour un arbre avec \(n\) points peut être calculée avec la formule suivante :
\[c(n) = 2 \left( \frac{n - 1}{2} \right)\]Cela représente la profondeur moyenne d’un arbre avec \(n\) points.
3. Score d’Anomalie et Fonction d’Isolement
L’algorithme calcule un score d’anomalie \(A(x)\) pour chaque point \(x_i\) basé sur sa profondeur d’isolement \(H(x)\) :
\[A(x) = 2^{\left( -\frac{H(x)}{c(n)} \right)}\]Où :
- \(H(x)\) est la profondeur d’isolement de x,
- \(c(n)\) est la profondeur d’isolement moyenne pour un arbre avec n points.
L’idée est que si la profondeur d’isolement H(x) est faible, alors \(A(x)\) sera proche de 1, ce qui indique que le point est une anomalie. En revanche, si \(A(x)\) est proche de 0, cela signifie que le point est normal.
4. Exemple Pratique d’Application dans notre Projet
Dans notre projet, nous avons utilisé Isolation Forest pour détecter des anomalies dans les logs de connexion des utilisateurs. Imaginons les étapes suivantes :
Données : Les logs contiennent des informations telles que l’ID utilisateur et l’heure de connexion .
Hypothèse : Nous soupçonnons qu’il y a des connexions suspectes, par exemple, des connexions à des heures inhabituelles.
Application de l’algorithme : Nous appliquons Isolation Forest pour détecter ces anomalies. Les logs sont transformés en un ensemble de données avec des caractéristiques telles que l’heure de connexion et l’ID utilisateur. L’algorithme divise ces données de manière récursive pour isoler les points inhabituels.
Détection : Si une connexion se fait par exemple à 3h du matin, et qu’elle est isolée plus rapidement que d’autres (qui se produisent habituellement entre 8h et 17h), cette connexion sera considérée comme une anomalie avec un score d’anomalie élevé.
5. Interprétation des Résultats et Détection d’Anomalies
Après avoir calculé le score d’anomalie pour chaque point de données, il est possible de fixer un seuil pour classifier les points comme anormaux ou normaux. Par exemple :
- Si le score d’anomalie est supérieur à un seuil \(t\), alors la connexion est marquée comme anormale.
- Si le score d’anomalie est inférieur à \(t\), alors la connexion est considérée comme normale.
Conclusion
L’algorithme Isolation Forest est une méthode puissante et efficace pour la détection d’anomalies dans des ensembles de données complexes, comme les logs de connexion. Grâce à sa capacité à isoler rapidement les anomalies, il est particulièrement utile dans des scénarios où la détection précoce de comportements inhabituels peut être cruciale pour la sécurité.
En appliquant cette méthode à nos logs de connexion, nous avons pu identifier rapidement des anomalies telles que des connexions à des heures inhabituelles ou des identifiants d’utilisateur qui ne correspondent pas aux comportements typiques. Cette approche nous permet de mettre en place des mesures préventives pour détecter et répondre aux incidents de sécurité de manière efficace.
D. Analyse du code de ML Isolation Forest
Ce code a pour objectif principal de traiter des logs d’un serveur Elasticsearch pour en extraire des informations sur les utilisateurs et leurs connexions, détecter des anomalies et visualiser ces anomalies à travers différents graphiques. Voici une explication détaillée de chaque section du code.
1. Connexion à Elasticsearch
1
2
3
4
5
6
7
8
es = Elasticsearch([{'scheme': 'http', 'host': 'localhost', 'port': 9200}])
# Vérifier la connexion
if es.ping():
print("Connecté à Elasticsearch")
else:
print("Échec de la connexion")
exit()
Objectif: La première partie établit une connexion à Elasticsearch, une base de données distribuée utilisée pour stocker, rechercher et analyser de grandes quantités de données en temps réel. L’URL de la connexion (localhost:9200) est définie et on vérifie la connectivité avec la méthode ping(). Si la connexion échoue, le programme s’arrête avec exit().
2. Extraction des logs depuis Elasticsearch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
query = {
"query": {"match_all": {}},
"_source": ["userID", "level", "timestamp", "logger"],
"size": 1000
}
results = es.search(body=query)
logs = []
for hit in results['hits']['hits']:
log = hit['_source']
if all(key in log for key in ['userID', 'level', 'timestamp']):
logs.append(log)
print(f"Logs filtrés: {len(logs)} logs")
Objectif: Un query est défini pour récupérer des logs d’Elasticsearch. Le filtre match_all permet de récupérer tous les documents disponibles, et l’extraction se limite à quatre champs (userID, level, timestamp, logger). Le résultat est ensuite filtré pour ne conserver que les logs ayant ces champs.
3. Traitement des données et création du DataFrame
1
2
3
4
5
6
7
8
data = []
for log in logs:
timestamp = log['timestamp']
try:
timestamp_dt = datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S.%f")
data.append([log['userID'], log['level'], timestamp_dt])
except ValueError:
continue
Objectif: Les logs extraits sont ensuite convertis en un format utilisable en DataFrame avec Pandas. Chaque timestamp est converti en un objet datetime pour faciliter les manipulations temporelles.
4. Analyse des connexions par utilisateur et heure
1
2
3
4
5
6
7
df = pd.DataFrame(data[:250], columns=["userID", "level", "timestamp"])
df['timestamp'] = pd.to_datetime(df['timestamp'])
df['hour'] = df['timestamp'].dt.hour
agg_df = df.groupby(['userID', 'hour', 'level']).size().reset_index(name='count')
pivot_table = agg_df.pivot_table(index='userID', columns='hour', values='count', aggfunc='sum', fill_value=0)
Objectif: Après avoir créé un DataFrame, les données sont regroupées par userID, hour (heure de la connexion) et level (niveau de log). Un pivot_table est ensuite généré pour préparer la visualisation de ces données sous forme de heatmap (carte de chaleur).
5. Visualisation de la heatmap
1
2
3
4
5
6
7
plt.figure(figsize=(18, 50))
sns.heatmap(pivot_table, cmap="YlOrRd", annot=True, fmt=".0f", cbar_kws={'label': 'Nombre de connexions'})
plt.title("Heatmap des connexions par utilisateur et heure (avec niveaux de log)")
plt.xlabel("Heure de connexion")
plt.ylabel("ID Utilisateur")
plt.yticks(rotation=360)
plt.show()
Objectif: Cette section crée une heatmap qui affiche le nombre de connexions par utilisateur et par heure, en utilisant la palette de couleurs YlOrRd (qui va du jaune au rouge). Chaque cellule est annotée avec la valeur correspondante. L’axe des X représente les heures, et l’axe des Y les userID.
6. Détection des anomalies avec Isolation Forest
1
2
3
4
5
6
7
8
9
10
11
12
user_connections = df['userID'].value_counts().reset_index()
user_connections.columns = ['userID', 'connection_count']
encoder_level = LabelEncoder()
df['level_encoded'] = encoder_level.fit_transform(df['level'])
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
df['anomaly'] = iso_forest.fit_predict(df[['hour', 'level_encoded']])
df = df.merge(user_connections, on='userID')
df_anomalies = df[df['anomaly'] == -1]
df_normal = df[df['anomaly'] == 1]
Objectif: Cette section utilise le modèle Isolation Forest pour détecter des anomalies dans les données en fonction de l’heure et du niveau de log. La méthode fit_predict() attribue une étiquette d’anomalie à chaque donnée : 1 pour normal et -1 pour anomalie. Ensuite, un merge est effectué pour ajouter les informations sur le nombre de connexions par utilisateur.
7. Visualisation des anomalies
1
2
3
4
5
6
7
8
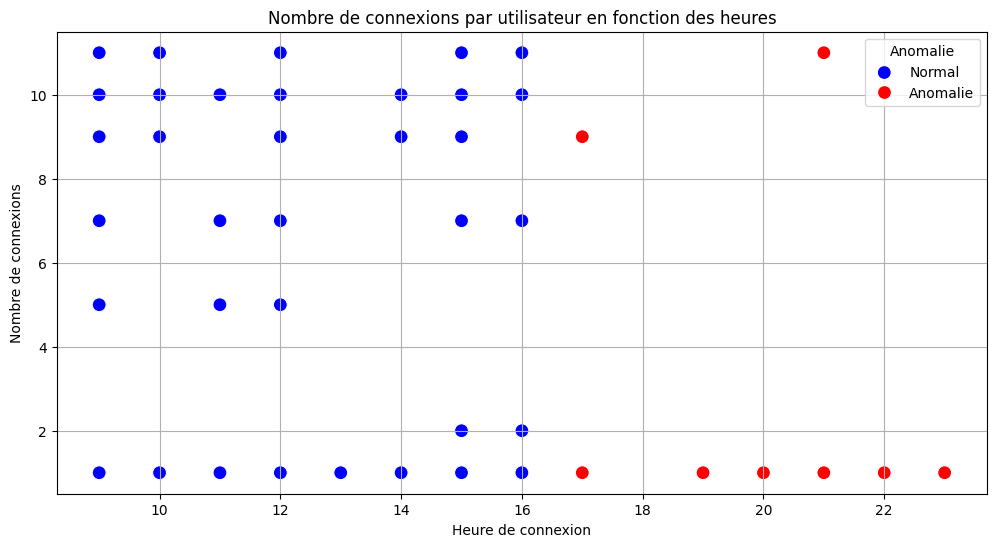
plt.figure(figsize=(12, 6))
sns.scatterplot(data=df, x='hour', y='connection_count', hue='anomaly', palette={1: "blue", -1: "red"}, s=100)
plt.title("Nombre de connexions par utilisateur en fonction des heures")
plt.xlabel("Heure de connexion")
plt.ylabel("Nombre de connexions")
plt.legend(title="Anomalie", labels=["Normal", "Anomalie"])
plt.grid()
plt.show()
Objectif: Un scatterplot est utilisé pour visualiser le nombre de connexions par utilisateur en fonction de l’heure, avec les anomalies colorées en rouge et les données normales en bleu. Cela permet d’identifier rapidement les comportements anormaux des utilisateurs.
8. Finalisation et traitement des anomalies
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
df['timestamp_dt'] = pd.to_datetime(df['timestamp'], errors='coerce')
df = df.sort_values(by='timestamp_dt')
df['hour'] = df['timestamp_dt'].dt.hour
encoder_userID = LabelEncoder()
encoder_level = LabelEncoder()
df['userID_encoded'] = encoder_userID.fit_transform(df['userID'])
df['level_encoded'] = encoder_level.fit_transform(df['level'])
features = df[['userID_encoded', 'level_encoded', 'hour']]
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
df['anomaly'] = iso_forest.fit_predict(features)
df['anomaly'] = df['anomaly'].map({1: 'Normal', -1: 'Anomalie'})
plt.figure(figsize=(14, 14))
sns.scatterplot(
x=df['timestamp_dt'], y=df['userID'],
hue=df['anomaly'], palette={'Normal': 'blue', 'Anomalie': 'red'}, s=50
)
plt.title('Détection des Anomalies en Fonction du Temps')
plt.xlabel('Heure')
plt.ylabel('Utilisateur')
plt.xticks(rotation=45)
plt.yticks(rotation=45)
plt.legend(title="Statut")
plt.show()
Objectif: Cette dernière section affine l’analyse des anomalies en réencodant les userID et les niveaux de logs, puis en utilisant de nouveau Isolation Forest pour détecter des anomalies dans les comportements des utilisateurs sur une période donnée. Un dernier scatterplot permet de visualiser les anomalies dans le temps.

Conclusion
Ce code permet d’effectuer une analyse approfondie des logs d’un serveur Elasticsearch, de détecter des anomalies dans les comportements des utilisateurs à l’aide de Isolation Forest, et de visualiser les résultats de manière claire à travers des heatmaps et des scatterplots. Cela pourrait être utilisé pour surveiller les comportements suspects dans des systèmes de production en temps réel, ou dans des environnements où la détection rapide des anomalies est cruciale.
3. Conclusion du projet
Ce projet visait à analyser des logs collectés depuis un serveur Elasticsearch pour détecter des anomalies dans les connexions des utilisateurs. En utilisant des techniques de prétraitement des données et de détection d’anomalies, plusieurs objectifs ont été atteints.
Collecte et Préparation des Données : Nous avons connecté un client Python à un serveur Elasticsearch pour récupérer des logs sous forme de documents JSON. Les données ont été filtrées et transformées en un format utilisable pour l’analyse, notamment en extrayant les informations essentielles comme l’ID utilisateur, le niveau de log, et l’horodatage.
Analyse des Connexions Utilisateurs : Grâce à la librairie
pandas, les logs ont été organisés et regroupés par utilisateur et heure. Des visualisations ont été créées sous forme de heatmap pour examiner les tendances des connexions au fil du temps et détecter les périodes de forte activité.Détection des Anomalies : L’algorithme
IsolationForest, un modèle d’apprentissage non supervisé, a été utilisé pour détecter les anomalies dans les connexions. L’algorithme a permis de classifier les événements comme “normaux” ou “anomalies” en fonction de la fréquence et du type de connexion des utilisateurs.Visualisation des Résultats : Plusieurs graphiques ont été produits pour illustrer les anomalies détectées. Par exemple, un graphique de dispersion a été utilisé pour représenter les anomalies en fonction de l’heure de connexion et du nombre de connexions, ce qui permet de visualiser les comportements suspects ou inhabituels.
Modèle Prédictif : L’encodeur de niveau de log et l’encodeur d’ID utilisateur ont préparé les données pour l’apprentissage supervisé, permettant au modèle
IsolationForestde mieux identifier les anomalies sur des caractéristiques spécifiques.
4. Perspectives
Le modèle développé peut être utilisé pour surveiller en temps réel les activités des utilisateurs sur un serveur, facilitant ainsi la détection de comportements anormaux, tels que des tentatives de connexion suspectes ou des actions malveillantes. Ce projet peut être étendu pour inclure plus de variables, telles que des adresses IP ou des types de connexions, afin d’améliorer la détection des menaces.
Dans un cadre plus large, ce type d’analyse pourrait être intégré à des systèmes de sécurité pour automatiser la détection des intrusions et alerter les administrateurs lorsqu’un utilisateur présente un comportement anormal, améliorant ainsi la sécurité du système global.